Not long ago, Intel teamed up with HPE (Chinese name: Huihe) and China Telecom Beijing Research Institute to release a technical white paper: "Finding an Effective Virtual Network Architecture for the Next Generation Telecom Infrastructure". The English name is: Finding an efficient virtual Network function architecture for next-generation telecommunications infrastructure (see the figure below), at the system level, elaborates on the latest work and achievements of the three companies in the field of promoting network function virtualization (NFV). In addition, at the Mobile World Congress in Shanghai this year, the prototype verification of this project was also publicly demonstrated at the HPE booth. At the same time, the next phase of the project will also be carried out smoothly.

As one of the main participants in this project, I saw that these phased results are constantly emerging. I naturally feel a sense of accomplishment. I also learned a lot during the project, and made many other business units from Intel. Colleagues, colleagues and friends of HPE and China Telecom. Today's article, I will be a technical interpretation of this white paper, will focus on the role and significance of FPGA in virtual network architecture such as NFV.
Attached to a photo of the Beijing Research Institute of China Telecom in May.


NFV and virtualization technology are very hot topics in recent years. It takes about dozens of blogs to deeply explore the meaning of NFV. In recent years, there have been many books on the market that have introduced NFV. Perhaps I will write a few articles separately to discuss what is the background and existence of NFV and NFV in a broad sense. But this article and the white paper are aimed at the application of NFV in telecommunications networks.
The telecommunications network is a major application scenario for NFV. One of the most direct drivers of its emergence is to support exponential bandwidth growth. It is predicted that global IP traffic will grow more than three times today compared to today. Today, in the Internet of Everything, especially when 5G, Internet of Things, autopilot and other technologies have become the focus of competition among major companies, all kinds of equipment and services need to be processed and supported by the telecommunications network and its data center. However, the traditional telecommunication infrastructure and data center are difficult to expand effectively. The main reasons are as follows:
Hardware level: The traditional telecommunication network infrastructure uses various types of dedicated hardware devices, such as various access devices, switches, routers, firewalls, and QoS. There are many problems with this. For example, poor compatibility between different devices, difficulty in maintenance and upgrade, easy monopolization of suppliers, and significant cost increase. If new functions need to be added, new hardware devices should be developed.
Software level: Different devices need their respective software to be configured and controlled, which makes it difficult to deploy and configure a wide range of functions at the administrator level, and needs to learn software configuration methods from devices of different vendors and specifications. If some network functions are implemented by software, the effective utilization rate of the server in the traditional implementation method is low, and the dynamic migration of the service cannot be performed, and the like.
Therefore, virtualization technology - more specifically, network function virtualization NFV technology has gradually become an effective way for major operators to solve the above problems. The European Telecommunications Standards Institute (ETSI) is a well-known diagram of NFV.
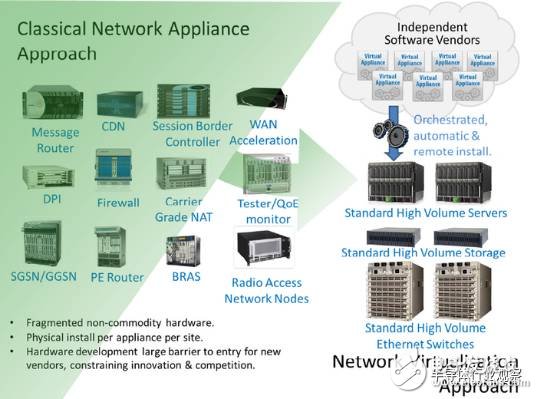
Overall, NFV leverages common servers (mostly based on Intel x86 processors), general-purpose storage devices, and general-purpose high-speed Ethernet switches to implement the various networking functions of traditional telecom network infrastructures compared to traditional approaches. Specifically, the network function is implemented in software in a general-purpose server, the data is stored using a general-purpose storage device, and network traffic is forwarded through a general-purpose network card and a high-speed switch. This theoretically solves the above-mentioned hardware-level problems: using general-purpose devices instead of dedicated devices, the data center's scalability can be improved without being constrained by a certain vendor, but it will reduce hardware procurement and deployment through open competition. the cost of.
In addition, with virtualization technology, the network functions are implemented in different virtual machines, so that the software level problem can be solved theoretically: that a specific application does not occupy all the resources of the server, and vice versa, one server can run multiple virtual machines at the same time. Machine or network service. At the same time, the expansion and migration of virtual machines in the data center is more convenient, and will not cause the service to go offline or be interrupted.
NFV and another technology: Software Defined Network (SDN) often comes together. One of their main core ideas is to separate the control and forwarding planes of the network. In this way, all data forwarding device devices can be controlled, configured, and managed at the same time, thereby avoiding the inefficiency of the administrator to separately configure each network device.
Quote the "China Telecom CTNet2025 Network Architecture White Paper":
"From the perspective of better adapting to Internet applications, the future network architecture must require the openness and standardization of network capability interfaces. Through software-defined network technologies, it can realize the scheduling and customization of network resources and capabilities for service-oriented, and further accelerate The platformization of network capabilities also needs to provide network programmable capabilities to truly realize the deep opening of network services."
Please note that in the previous statement I used a lot of "theoretical" how it is because the above advantages about NFV are many people's good imagination and vision. In actual engineering practice, designing and implementing an effective NFV architecture faces many problems. For example, in different application scenarios, the types of network load are varied, and many applications require wire-speed processing, such as QoS and traffic shaping (described in the previous blog post), VPN, firewall, network address translation, encryption and decryption, real-time. Monitoring, Deep Packet Inspection (DPI), and more. Even with dedicated software development libraries such as DPDK, the current use of software to achieve wire-speed processing of these network services is technically very difficult, and the network functions implemented by software are difficult to compare with proprietary hardware in performance. In this way, people will in turn question the starting point and motivation of using NFV. At the same time, in view of the fact that NFV is still in the stage of exploration and exploration, many related agreements and standards have not yet been determined, which also makes many companies hesitate to invest a lot of resources to carry out preliminary research work.
Therefore, how to effectively implement these virtualized network functions (VNF) is the main work of our previous stage and the main issues discussed in this white paper.
Effective implementation of virtual network function (VNF)
Here, the "effectiveness" of implementing virtual network functions is mainly reflected in the following aspects:
1.VNF must be very flexible and easy to use;
2. Easy to scale on a large scale, not limited to a certain application scenario or network;
3. Performance should be no lower than or even higher than dedicated hardware.
In this regard, several potential development directions are given in the white paper for reference:
1. Separation and independent expansion of the control plane and the forwarding plane.
2. Design and optimize and standardize the forwarding surface with programmable capabilities.
In the application scenario of the telecommunication network, a typical application of the NFV is the virtualized broadband remote access service vBRAS, which is also called virtual broadband remote access server, which is also called virtual broadband network gateway. There may be many virtual network functions in vBRAS, such as Remote Authentication Dial-In User Service (RADIUS), Dynamic Host Configuration Protocol (DHCP), and DPI and firewall mentioned before. , QoS, etc.
An important finding is that these web applications can be divided into two categories based on the needs of computing resources. One type does not require a large amount of computing resources such as RADIUS and DHCP. At the same time, many of these applications belong to the control plane. This type of application is therefore well suited for direct placement on the control plane and has excellent vertical and horizontal scalability, and is well suited for implementation with general purpose computing and storage devices.
Another type of application often requires a lot of computing power, such as traffic management, routing and forwarding, packet processing, etc., and usually requires online speed (such as 40Gbps, 100Gbps or higher) for processing. Such applications are often part of the data plane. For the data plane, it also needs to support a large number of computationally intensive network functions, in order to distinguish it from the use of proprietary hardware, in line with the original intention of NFV technology. In summary, the data plane should have the following two main capabilities:
1. High-throughput complex packet processing at wire speed;
2. Support multiple network functions at the same time, with strong programmability.
However, if you implement it directly using a software method, these two functions are difficult to satisfy at the same time. Therefore, we have adopted FPGA as an intelligent hardware acceleration platform, which solves both the processing speed and the programmability. First, FPGAs are used as hardware accelerators because of their inherently superior hardware parallelism in packet processing compared to pure software methods. Second, FPGAs have flexible programmability compared to traditional proprietary hardware devices to support a variety of applications.
Virtual Broadband Remote Access Service: Evolution from BRAS to vBRAS
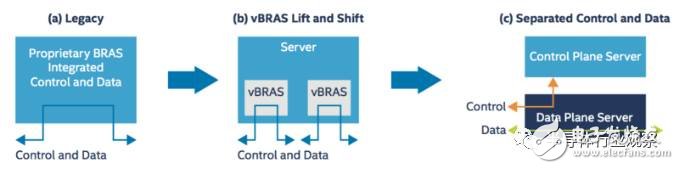
Figure 1: Evolution of vBRAS
The above picture shows us the three main processes of the traditional BRAS evolution to vBRAS:
1. In the first phase, the traditional BRAS uses dedicated equipment, and the control plane and the forwarding plane are tightly coupled. The figure shows that the control path and the data path are coincident with each other.
2. In the second phase, virtualization technology was adopted, and a dedicated BRAS device was replaced by a server, and multiple vBRASs were implemented using software and virtual machines. But at the same time, it can be seen that the control plane and the forwarding plane are still coupled to each other. Due to the large difference in performance between the two, this implementation can easily cause performance bottlenecks in the data path, or occupy the bandwidth of the control plane due to excessive data path traffic. Conversely, the flow of the control plane affects the ability of the line rate packet processing of the data plane.
3. In the third stage, virtualization technology is adopted, and the control plane and the forwarding plane are separated from each other. As can be seen from the figure, the control plane and the forwarding plane are implemented separately by two servers, and the control traffic and the forwarding traffic do not affect each other. In addition, control traffic can flow in both directions between the data/forward server and the control server, enabling control over the forwarding plane.
This third phase is the latest achievement of joint research and development by Intel, HPE and China Telecom North Research Institute. Next, the technical details will be explained in detail.
High-performance vBRAS design method
Designing to implement the high-performance vBRAS solution in the third phase above requires vBRAS-c (control) and vBRAS-d (data), namely vBRAS control device and vBRAS data device. Both types of devices should be implemented using a standardized, generic server. In addition, for vBRAS data devices, special optimization and acceleration for computationally intensive applications is required to enable high throughput, low latency packet processing.
The figure below shows the design of vBRAS-c and vBRAS-d in this application example.
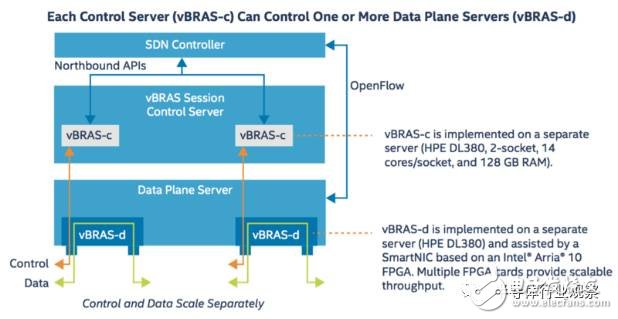
Figure 2: vBRAS's transfer separation architecture
For the vBRAS-c node, its important design idea is lightweight and virtualized, which makes it easy to extend and migrate in the data center or cloud, and can be distributed to control multiple data plane nodes. So in this example, vBRAS-c is implemented by a separate HPE DL380 server. The DL380 server contains two CPU sockets, each with a 14-core Xeon processor. The total memory of the server is 128GB. For network interfaces, vBRAS-c can use a standard network card for network communication, such as one or more Intel X710 10GbE network cards to meet the control plane traffic requirements. The specific vBRAS control application is implemented in the virtual machine, and multiple virtual machines are uniformly controlled by the SDN controller.
For vBRAS-d nodes, the whole is also implemented by a separate DL380. For the optimization acceleration mentioned above, this example uses an Arria10 FPGA-based intelligent NIC acceleration network function, such as line rate processing QoS and multi-level traffic shaping. In a DL380, multiple FPGA intelligent network cards can be inserted to achieve parallel data processing and double the data throughput. At the same time, the vBRAS-d node interacts with the SDN controller through OpenFlow, and one vBRAS-c device can control multiple vBRAS-d devices.
Intelligent network card resolution based on Arria10 FPGA
The benefits of using an FPGA Smart NIC for network acceleration are as follows:
1. Free up the valuable CPU core, and offload the data processing originally implemented in the CPU to the FPGA for accelerated implementation. In this way, the CPU can be used for other work, and further realize the effective use of resources on the basis of virtualization.
2. FPGA has low power consumption and flexible programmable features. As mentioned in the white paper, after implementing hardware QoS and multi-level traffic shaping on the selected Arria10 GT1150 device, it only occupies 40% of the logic resources of the FPGA. In other words, 60% of the resources can be used for other network functions processing and acceleration. At the same time, the FPGA can be programmed at any time, so the acceleration of various network functions can be completed with a set of hardware devices, without the need to replace the accelerator card or other hardware devices. Even user-defined functions can be implemented without the need for proprietary equipment. This is a good balance between high performance and high versatility.
3. FPGA can perform high-speed parallel packet processing, and it is widely used in the field of network communication, and the solution is rich and mature.
The following figure summarizes the data path design for packet forwarding implemented in an FPGA in this example.
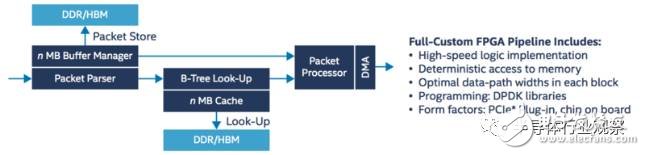
Figure 3: Data Path for FPGA Packet Processing
As can be seen from the figure, this design contains multiple modules, such as Parser, Look-Up, Buffer Manager, Packet Processor, and memory controller and DMA. After the data packet enters the FPGA, it performs feature extraction, classification, and search through each module in turn, and interacts with the CPU through PCIe and DMA if necessary. At the same time, Buffer Manager performs traffic control, QoS, and traffic shaping operations on packets from different sources.
In addition, this FPGA intelligent network card supports a variety of packet processing modes, that is, the data packet can be completely processed inside the FPGA and then forwarded without going through the CPU; the data packet can also be transmitted to the CPU through PCIe, and processed by the DPDK, and then passed. FPGA forwarding; or a combination of the two, some functions are implemented in the CPU, and another part is offloaded to the FPGA. Visibility is high.
Performance Testing
The figure below shows the hardware setup for performance testing.
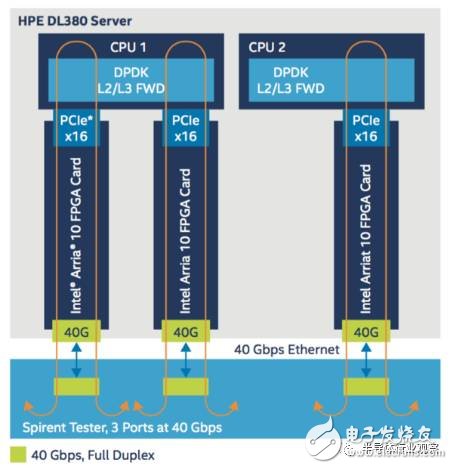
Figure 4: Server and FPGA Architecture for the Data Plane
As can be seen, one DL380 server has three independent FPGA intelligent network cards inserted, each supporting 40Gbps data throughput, so the total throughput supported by one vBRAS-d server is 120Gbps. Each NIC is connected to the CPU via a PCIex16 interface, runs the DPDK L2/L3 FWD application in the CPU, forwards the data back to the FPGA, and then performs QoS and data shaping in the FPGA. In the test, the generation and reception of traffic is achieved by the Spirent tester.
For QoS, each intelligent network card can support 4000 users, so a single server supports 12,000 users. Each user supports 2 priority levels, and the bandwidth allocated to each user can be programmed. For example, if each user allocates 8.5 Mbps bandwidth, the total traffic of a single server after traffic shaping is enabled should be 12000 x 8.5 = 102 Gbps, as shown in the following figure.
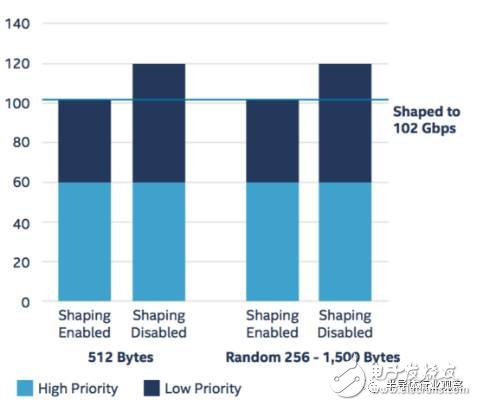
Data plane performance test results
We see that when the packet is 512 bytes long, the traffic shaping function is disabled, and there is no loss of high priority traffic and low priority traffic, each of which is 60 Gbps (the actual traffic for each user is 5 Mbps high priority). +5Mbps low priority), so the total traffic is 120Gbps. After traffic shaping is enabled, high-priority traffic is not lost and is still 60Gbps. For low priority, since each user allocates 8.5 Mbps of bandwidth and high priority already occupies 5 Mbps of it, only 3.5 Mbps of bandwidth is left for low priority traffic to pass. It can be seen that the low priority traffic is limited, and the total traffic becomes 3.5Mx12000=42 Gbps, so that the total traffic becomes 102 Gbps. This generally demonstrates that a single vBRAS-d node can support more than 100 Gbps of traffic processing.
In addition, some power consumption tests have been performed to compare the performance. I have selected a result graph here as shown below.
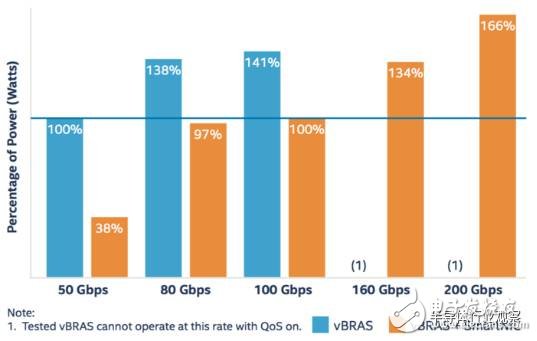
Figure 5: Comparison of total energy performance ratios at different bandwidths
This figure shows a series of comparisons of total power performance ratios when implementing different bandwidths. The power-to-performance ratio is defined as the total power consumption (kW) required to achieve 1Tbps. In the figure, the power performance ratio of the vBRAS without the FPGA intelligent network card at 50 Gbps is taken as the reference value (100%). As can be seen from the figure, the vBRAS+FPGA intelligent network card solution can always reduce the total power consumption by more than 40%, up to 60%. This further confirms the benefits of using FPGAs for network function acceleration as explained above.
Other performance tests and comparisons are not repeated here, and the details can be seen in the white paper. Overall, the vBRAS+FPGA Smart NIC solution reduces power consumption by approximately 50% and delivers more than 3x performance improvement over traditional vBRAS server + standard NIC solutions.
Conclusion
This white paper shows us the latest work done by industry-leading companies in the field of NFV and SDN, especially the use of FPGAs as a hardware acceleration platform to offload and accelerate network functions. This can significantly increase the utilization of hardware resources, while at the same time bringing performance and power consumption down, reducing deployment and operating costs. At the same time, combined with the dynamics of other companies in the industry, major Internet companies, cloud service providers, and telecom network providers are all trying to deploy FPGAs in their data centers. Microsoft's Azure cloud services have already adopted Intel FPGAs for hardware. accelerate. Therefore, how to effectively design heterogeneous computing microstructures such as CPU+FPGA, how to achieve efficient management and allocation of computing, control and storage resources in a narrow and broad sense, how to design efficiently in the data center, and how to design a business The model to clarify the location and role of the FPGA in the entire system will be a research hotspot in the future.
About the Author
Dr. Shi Wei received his Ph.D. degree from the Electronics Department of Imperial College London, and joined Intel's Programmable Solutions Group as a senior FPGA R&D engineer. Ishigaki has many years of experience in academic research and industrial development in the semiconductor industry, especially in the fields of FPGA, high performance and reconfigurable computing, computer networking and virtualization. He has published papers in leading conferences and journals such as DAC, FCCM, and TVLSI. In the industry, he is mainly engaged in the research and development and innovation of FPGAs for data center network accelerators, network function virtualization, high-speed wired network communication and other related technologies.
25 Ft Ethernet Cable,Ethernet Cable Cat 6,Best Lan Cable,75 Ft Ethernet Cable
Zhejiang Wanma Tianyi Communication Wire & Cable Co., Ltd. , https://www.zjwmty.com