Recently, IBM announced that they used a set of ad datasets released by Criteo Labs to train logistic regression classifiers, running their own machine learning library Snap ML on POWER9 servers and GPUs, which is 46 times faster than previous best results from Google. .

NVIDIA CEO Wong Yan Hoon and IBM Senior Vice President John Kelly at the Think Conference
Recently, at the IBM THINK conference in Las Vegas, IBM announced that they have achieved significant breakthroughs in AI performance with new software and algorithms optimized for their hardware, including a combination of POWER9 and NVIDIA® V100TM GPUs.
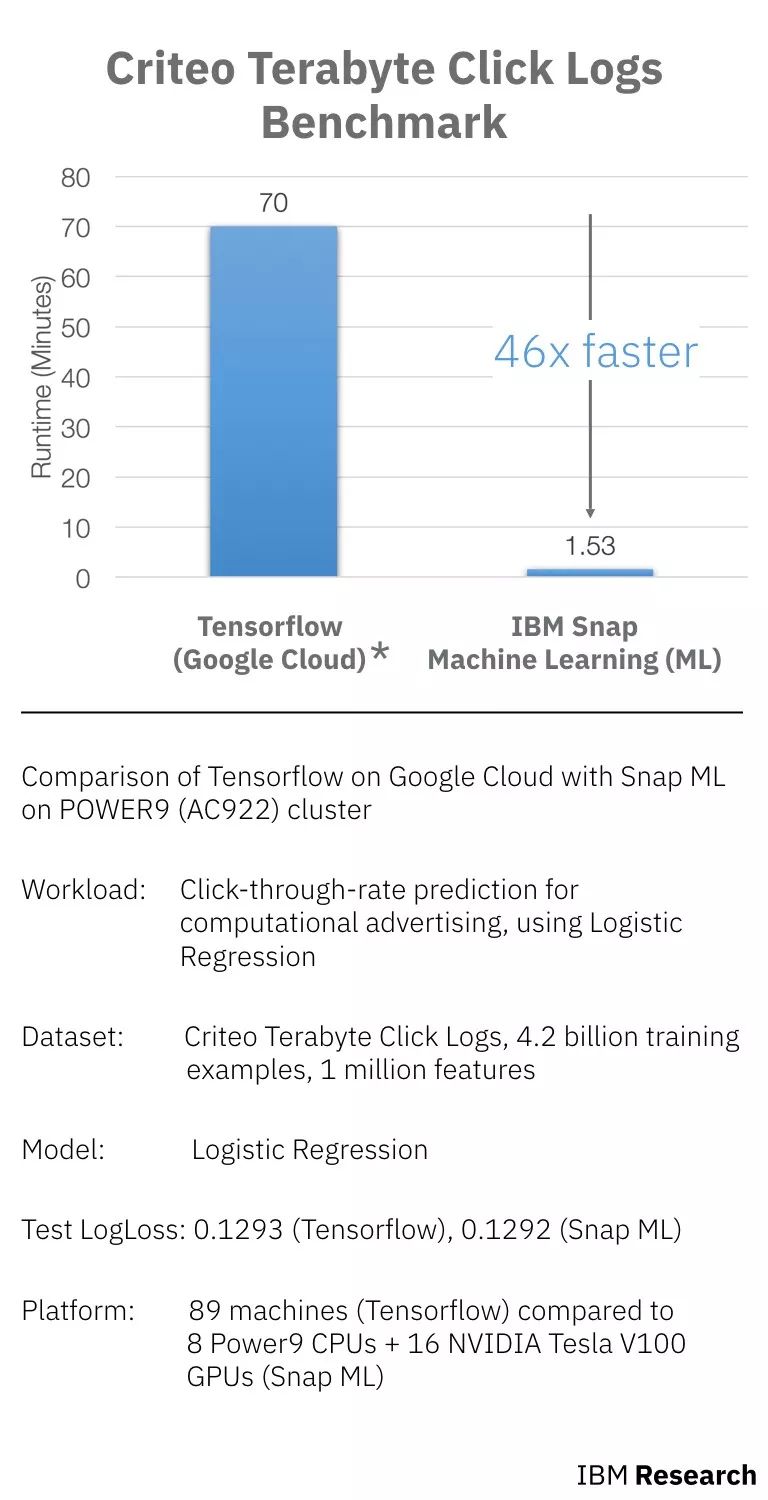
Comparison of IBM Snap on TensorFlow and POWER9 (AC922) cluster on Google Cloud (runtime contains data loading time and training time)
As shown above, the workload, dataset, and model are all the same, comparing the time spent training with TensorFlow on Google Cloud and Snap ML training on Power9. Among them, TensorFlow uses 89 machines (60 working machines and 29 parameter machines), and Snap ML uses 9 Power9 CPUs and 16 NVIDIA Tesla V100 GPUs.
Compared to TensorFlow, Snap ML gets the same loss, but is 46 times faster.
How to achieve it?
Snap ML: Actually 46 times faster than TensorFlow
As early as February last year, Google software engineer Andreas Sterbenz wrote a blog about using Google Cloud ML and TensorFlow for large-scale forecasting of ads and recommended clicks.
Sterbenz trained a model to predict the number of ad clicks displayed in Criteo Labs, which are over 1TB in size and contain eigenvalues ​​and click feedback from millions of display ads.
Data pre-processing (60 minutes) is followed by actual learning, using 60 working machines and 29 parametric machines for training. The model took 70 minutes to train and assessed the loss to be 0.1293.
Although Sterbenz subsequently used different models to get better results and reduced the evaluation loss, it took longer to end up using a deep neural network with three epochs (measuring the number of times all training vectors were used to update the weights). It took 78 hours.
But IBM's own training library running on POWER9 servers and GPUs can outperform 89 machines on Google's Cloud Platform in basic initial training.
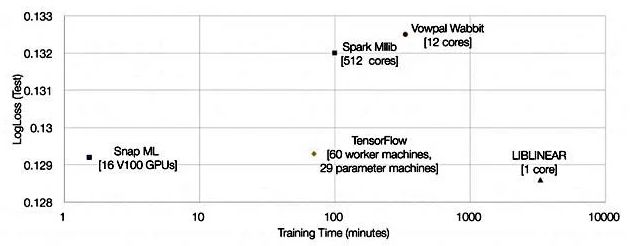
They showed a chart showing Snap ML, Google TensorFlow, and three other comparisons:

How is it 46 times faster than TensorFlow?
Researchers say that Snap ML has multiple levels of parallelism, allowing workloads to be distributed among different nodes in the cluster, utilizing accelerator units, and exploiting the multicore parallelism of individual compute units.
1. First, the data is distributed across the various worker nodes in the cluster.
2. On the node, the data is separated between the main CPU and the accelerated GPU running in parallel between the CPU and the GPU.
3. The data is sent to multiple cores in the GPU, and the CPU workload is multi-threaded
Snap ML has a nested hierarchical algorithmic function that takes advantage of these three levels of parallelism.
In short, the three core features of Snap ML are:
Distributed Training: Snap ML is a data-parallel framework that scales and trains on large data sets that can exceed the memory capacity of a single machine, which is critical for large applications.
GPU Acceleration: A specialized solver is implemented to take advantage of the GPU's massively parallel architecture while maintaining data location in GPU memory to reduce data transfer overhead. To make this approach scalable, with some recent advances in heterogeneous learning, GPU acceleration can be achieved even if only a fraction of the data that can be stored in the accelerator's memory is available.
Sparse data structure: Most machine learning data sets are sparse, so when applied to sparse data structures, some new optimizations are applied to the algorithms used in the system.
Technical process: 0.1292 test loss achieved in 91.5 seconds
Set the Tera-Scale Benchmark first.
Terabyte Click Logs is a large online advertising dataset published by Criteo Labs for research in distributed machine learning. It consists of 4 billion training samples.
Each sample has a "tag" that is whether the user clicks on the online ad and a corresponding set of anonymous features. Based on these data, the machine learning model is trained with the goal of predicting whether new users will click on the ad.
This data set is currently one of the largest public data sets, collected within 24 days, collecting an average of 160 million training samples per day.
To train the complete Terabyte Click Logs dataset, the researchers deployed Snap ML on four IBM Power System AC922 servers. Each server has four NVIDIA Tesla V100 GPUs and two Power9 CPUs that communicate with the host via the NVIDIA NVLink interface. The servers communicate with each other through the Infiniband network. When training the logistic regression classifier on such an infrastructure, the researchers achieved a test loss of 0.1292 in 91.5 seconds.
Look again at the picture in the previous article:
When deploying GPU acceleration for such large-scale applications, a major technical challenge arises: the training data is too large to be stored in the memory available on the GPU. Therefore, during training, you need to selectively process the data and move it in and out of the GPU memory repeatedly. To explain the runtime of the application, the researchers analyzed the time spent in the GPU core and the time it took to replicate the data on the GPU.
In this study, a small portion of the data from Terabyte Clicks Logs was used, including the initial 200 million training samples, and two hardware configurations were compared:
An Intel x86-based machine (Xeon Gold 6150 CPU @ 2.70GHz) with an NVIDIA Tesla V100 GPU connected using a PCI Gen 3 interface.
An IBM POWER AC922 server connected to four Tesla V100 GPUs using the NVLink interface (in comparison, only one of the GPUs is used).
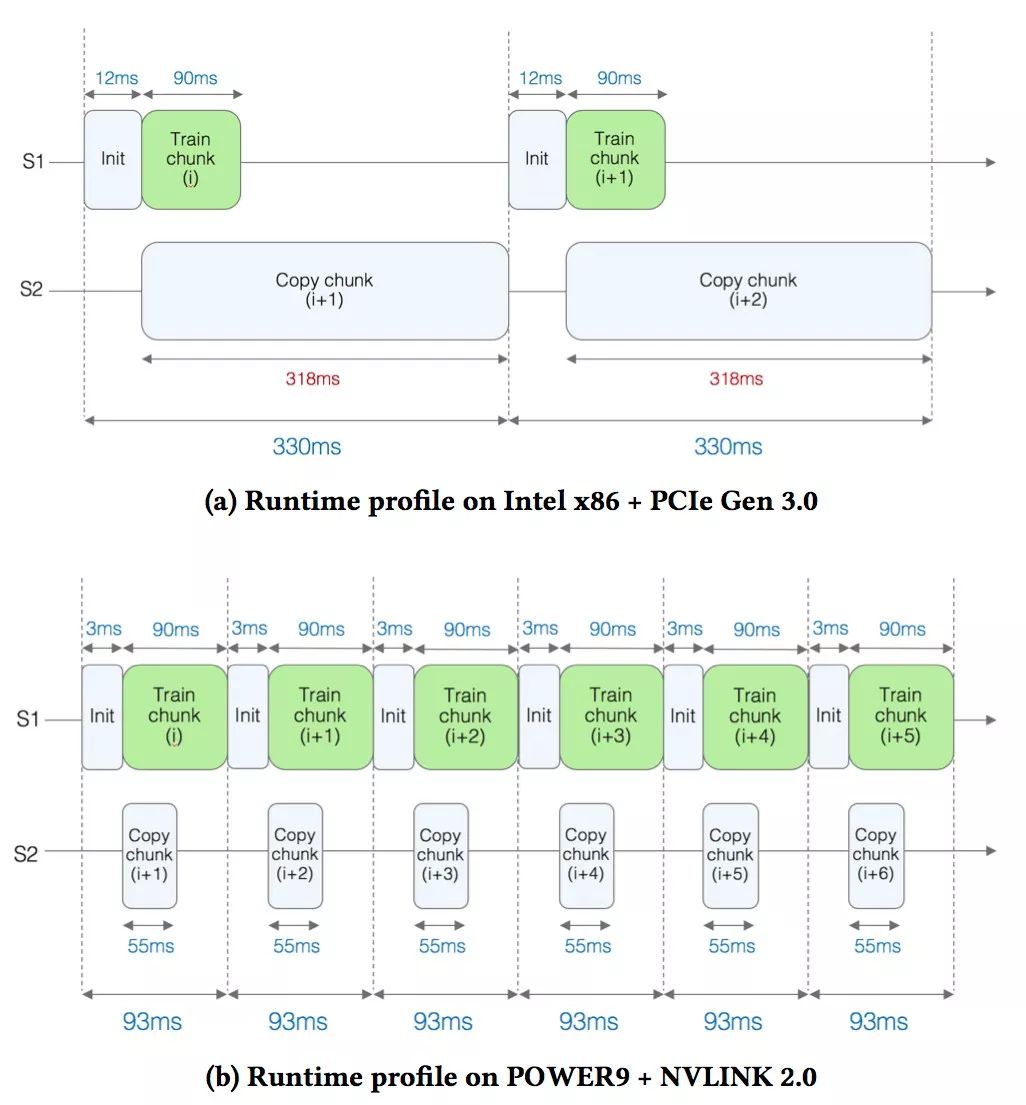
Figure a shows the performance analysis results for the x86 based setup. You can see the two lines S1 and S2. On the S1 line, the actual training is about to be completed (ie, the logical regression kernel is called). The time to train each block is approximately 90 milliseconds (ms).
While training is in progress, on the S2 line, the researchers copy the next block of data onto the GPU. Observing that copying data takes 318 milliseconds, which means that the GPU has been idle for quite some time, and the time to copy data is clearly a bottleneck.
In Figure b, for POWER-based settings, because NVIDIA NVLink provides faster bandwidth, the time to copy the next block to the GPU is significantly reduced to 55 ms (almost 6 times less). This acceleration is due to hiding the data replication time behind the kernel execution, effectively eliminating the replication time on the critical path and achieving a 3.5x acceleration.
IBM's machine learning library provides very fast training speeds, training mainstream machine learning models on modern CPU/GPU computing systems, training models to discover new interesting patterns, or re-creating new data when available. Train existing models to maintain speed at the line speed level (the fastest speed the network can support). This means lower user computing costs, less energy consumption, more agile development and faster completion times.
However, IBM researchers did not claim that TensorFlow did not take advantage of parallelism and did not provide any comparison between Snap ML and TensorFlow.
But they did say: "We implemented a specialized solution to take advantage of the massive parallel architecture of the GPU while respecting the data area in the GPU memory to avoid large data transfer overhead."
According to the article, the AC922 server with NVLink 2.0 interface is faster than the Xeon server (Xeon Gold 6150 CPU @ 2.70GHz) with PCIe interface of its Tesla GPU. The PCIe interface is the interface of the Tesla GPU. "For PCIe-based settings, we measured an effective bandwidth of 11.8GB / sec. For NVLink-based settings, we measured an effective bandwidth of 68.1GB / sec."
Training data is sent to the GPU and processed there. The NVLink system sends blocks of data to the GPU at a much faster rate than the PCIe system for 55ms instead of 318ms.
The IBM team also said: "When applied to sparse data structures, we have made some new optimizations to the algorithms used in the system."
In general, it seems that Snap ML can make more use of Nvidia GPUs, transferring data over NVLink faster than on PCIe links on x86 servers. But I don't know how the POWER9 CPU compares with the speed of Xeons. IBM has not publicly released any direct comparison between POWER9 and Xeon SP.
So it can't be said that Snap ML is much better than TensorFlow before running two suckers on the same hardware configuration.
Whatever the reason, the 46-fold drop was impressive and gave IBM a lot of room to push its POWER9 server as a place to plug in Nvidia GPUs, run Snap ML libraries, and machine learning.
Wuxi Doton Power , http://www.dotonpower.com