The upgrade of the experience of the LinkedIn virtual reality device is closely related to the processor and display technology, and the interaction with the virtual reality device is also very important. Whether in VR or AR equipment, voice, somatosensory, and gesture recognition may become interactive ways to enhance the experience. This article will introduce the mainstream optical gesture recognition technology.
Talking about gesture recognition technology, from simple rough to complex, can be roughly divided into three levels: 2D hand-type recognition, 2D gesture recognition, 3D gesture recognition.
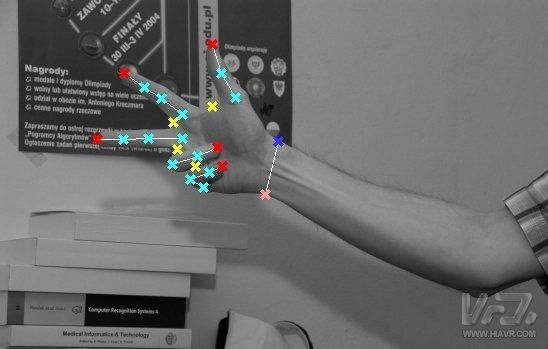
Before we discuss gesture recognition specifically, we need to know the difference between two-dimensional and three-dimensional. Two-dimensional is just a plane space. We can use the coordinate information (X coordinate, Y coordinate) to represent the coordinate position of an object in two-dimensional space, just like a picture appears on a wall. On the basis of this, three-dimensional information of “depth†(Z coordinate) is added, which is not included in the two-dimensional. The “depth†here is not the depth that we describe in real life. This “depth†expresses “deepâ€, and it is understood that it is more appropriate to the “distance†of the eyes. Like a goldfish in a fish tank, it can swim up and down in front of you, or it can be farther or closer to you.
The first two gesture recognition techniques are based entirely on the two-dimensional level. They only require two-dimensional information without depth information as input. Just as photographs taken at ordinary times contain two-dimensional information, we only need to use two-dimensional images captured by a single camera as input, and then use computer vision technology to analyze the input two-dimensional images and obtain information to achieve gestures. Identification.
The third gesture recognition technology is based on the three-dimensional level. The fundamental difference between 3D gesture recognition and 2D gesture recognition is that the input needed for 3D gesture recognition is information that contains depth, which makes 3D gesture recognition much more complex in both hardware and software than 2D gesture recognition. . For general simple operations, such as just wanting to pause or resume playing the video, 2D gestures are sufficient. However, for some complex human-computer interactions, interaction with 3D scenes must include depth information.
2D hand recognition
Two-dimensional hand-type recognition, also known as static two-dimensional gesture recognition, identifies the simplest type of gesture. This technique, after acquiring two-dimensional information input, can identify several static gestures such as making a fist or five fingers open. Its representative company is Flutter, which was acquired by Google a year ago. After using his home software, users can control the player with several hands. When the user lifts the palm of his hand and puts it in front of the camera, the video starts playing; before putting the palm to the camera, the video pauses again.
“Static†is an important feature of this 2D gesture recognition technology. This technology can only recognize the “state†of the gesture, but cannot perceive the “continuous change†of the gesture. For example, if this technique is used for guessing, it can recognize the gesture states of stone, scissors, and cloth. But it knew nothing about the other gestures. So this technology is a pattern matching technology in the end, through the computer vision algorithm to analyze the image, and compare with the preset image mode to understand the meaning of this gesture.
The inadequacies of this technology are obvious: only the preset state can be identified, the expansion is poor, and the sense of control is weak. The user can only achieve the most basic human-computer interaction function. But it is the first step in identifying complex gestures, and we can indeed interact with the computer through gestures, or is it cool? Imagine you are busy eating, just make a gesture out of thin air, the computer can switch to the next video It's much easier than using a mouse to control!
2D gesture recognition
Two-dimensional gesture recognition is slightly more difficult than two-dimensional hand-type recognition, but it still contains no depth information and stays on the two-dimensional level. This technique not only recognizes the hand type, but also recognizes some simple two-dimensional gestures such as waving at the camera. Its representative companies are PointGrab, EyeSight and Extreme Reality from Israel.
Two-dimensional gesture recognition has dynamic features that can track the movement of gestures, and then identify complex movements that combine gestures and hand movements. In this way, we really extend the scope of gesture recognition to the two-dimensional plane. Not only can we control the play/pause of the computer through gestures, we can also achieve forward/backward/upward/downward scrolling through these complex operations that require two-dimensional coordinate change information.
Although this technology does not differ from the two-dimensional hand-type recognition in terms of hardware requirements, thanks to more advanced computer vision algorithms, more abundant human-computer interaction content can be obtained. In the use of experience has also been improved a grade, from pure state control, into a richer plane control. This technology has been integrated into television, but it has not become a common control method.
3D gesture recognition
What we want to talk about next is the highlight of today's gesture recognition field - 3D gesture recognition. The input required for the three-dimensional gesture recognition is depth-information that recognizes various hand types, gestures, and actions. Compared with the first two kinds of two-dimensional gesture recognition technology, three-dimensional gesture recognition can no longer use only a single common camera, because a single ordinary camera can not provide depth information. To obtain depth information requires special hardware. At present, there are mainly three hardware implementations in the world. With the addition of new advanced computer vision software algorithms, 3D gesture recognition can be achieved. Let's let Xiao Bian give you a three-dimensional imaging hardware principle based on 3D gesture recognition.
1. Structure Light
The representative application of structured light is the Kinect generation of PrimeSense.
The basic principle of this technique is to load a laser projector and place a grating with a special pattern outside the laser projector. The laser will refract when projecting through the grating, so that the laser finally falls on the surface of the object. Generate displacement. When the object is closer to the laser projector, the displacement caused by the refraction is smaller; when the object is farther away, the displacement caused by the refraction will be correspondingly larger. At this time, a camera is used to detect the pattern projected onto the surface of the object. Through the displacement of the pattern, the position and depth information of the object can be calculated by an algorithm, and the entire three-dimensional space can be restored.
According to the Kinect generation of structured light technology, because of the reliance on the displacement of the laser spot after the refraction occurs, the displacement due to refraction is not obvious at too close distances. Using this technique, the depth information cannot be calculated with too high accuracy. , so 1 to 4 meters is its best application range.
2. TIme of Flight
Light-flying time is a technology used by SoftKineTIc, which provides Intel with a three-dimensional camera with gesture recognition. At the same time, this hardware technology is also used by Microsoft's new generation of Kinect.
The basic principle of this technique is to load a light emitting element, and the photons emitted by the light emitting element will reflect back after hitting the surface of the object. Using a special CMOS sensor to capture these photons emitted by the light emitting element and reflected back from the surface of the object, the photon flight time can be obtained. According to the photon flight time, the distance of the photon flight can be calculated and the depth information of the object can be obtained.
In terms of calculation, light fly time is the simplest in three-dimensional gesture recognition and does not require any calculation in computer vision.
3. Multi-angle imaging (MulTI-camera)
The representative product of this technology for multi-angle imaging is Leap MoTIon's eponymous product and Usens' Fingo.
The basic principle of this technique is to use two or more cameras to capture images at the same time, just as if humans used the eyes and insects to observe the world with multi-eye compound eyes and compare the images obtained by these different cameras at the same time. An algorithm is used to calculate depth information for multi-angle 3D imaging.
Here we explain briefly with two camera imaging:
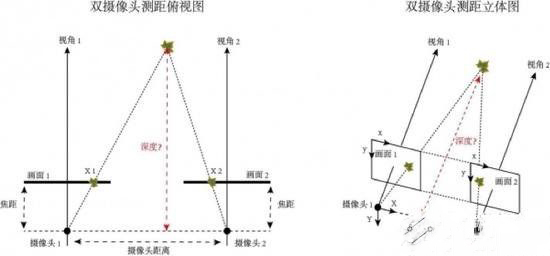
Dual camera ranging is based on geometric principles to calculate depth information. Using two cameras to take pictures of the current environment, two different views of the same environment are actually taken to simulate the principle of the human eye. Because the parameters of the two cameras and their relative positions are known, as long as the position of the same object (Maple Leaf) is found on different screens, we can calculate the object (maple) from the camera by the algorithm. The depth of the.
Multi-angle imaging is the lowest hardware requirement in 3D gesture recognition technology, but it is also the most difficult to achieve. Multi-angle imaging does not require any additional special equipment and is completely dependent on computer vision algorithms to match the same target in two images. Compared with the disadvantages of high cost and large power consumption of structured light or optical fly-time, multi-angle imaging can provide “affordable†3D gesture recognition.
We design, engineer and fabricate mold tooling, both standard and custom. We continuously design custom tooling to satisfy our customer needs. These tools are built for machines such as Newbury, Autojector, Ameriplas, Multiplas, etc. Our Solidworks 3D design capabilities represent the leading edge in the industry.
We provide training and know-how to our customers. We offer this unique advantage to companies interested in On-site training to assist in the development of in-house capabilities. Our company can become your "over -mold engineering department" and can provide quick turn-around, high quality for customers' the complete cable set with wire harness, plastic, silizone o-ring, metal terminal, or plate, etc. Try to give you the whole supporting service.
Molded Plastic Products,Waterproofing Plastic Box,Plastic Connectors,Plastic Cap,Plastic Bushing
ETOP WIREHARNESS LIMITED , https://www.wireharnessetop.com