In the past few years, deep learning (DL) architectures and algorithms have made milestones in many areas, such as image recognition and language processing.
At first, the application of deep learning in natural language processing (NLP) was not obvious, but later there were many heavyweight results, such as named entity recognition (NER), part of speech tagging (POS tagging) or text sentiment analysis (sentiment analysis). ) are all methods of neural network models that go beyond traditional models. However, the progress made in the field of machine translation is the most significant.
Javier Couto is a research and development scientist at tryo labs, specializing in NLP technology. This article is a summary of his application of deep learning technology in the NLP field in 2017. It may not be comprehensive, but it is a result that he considers valuable and meaningful. Couto said that 2017 is a very meaningful year for the NLP field, and with the application of deep learning, NLP technology will continue to develop.
From training word2vec to using pre-trained models
In general, word embeddings is the most famous deep learning technique related to NLP. It follows the distribution hypothesis proposed by Harris. The distribution hypothesis is derived from the semantic principle in linguistics. Words that appear to be in a similar context may be used to express similar meanings.
Distributed vector of words
Although the famous algorithms such as word2vec and GloVe cannot be counted as deep learning frameworks (word2vec only involves shallow neural networks, and GloVe is a matrix-based approach), many of the models trained with them are input to the depth for NLP. In the learning tool. So using word embedding in this area is usually a very good practice.
Initially, for a problem that requires word embedding, we tend to train our own models from a corpus associated with the field. However, this method is not suitable for all situations, so a pre-training model has emerged. By training on Wikipedia, Twitter, Google News, and other web pages, these models make it easy to integrate word embedding into deep learning algorithms.
This year, many people believe that pre-trained word embedding models remain a key issue in NLP. For example, fastText, published by Facebook Artificial Intelligence Lab (FAIR), is a pre-trained word embedding model that supports 294 languages ​​and has made a significant contribution to the NLP field. In addition to supporting multiple languages, fastText can also decompose words into character n-grams, giving a vector representation even if it encounters an OOV problem in the dictionary. Because rare words in some specific fields can still be broken down into character n-grams, they can share these n-grams with generic words. Neither word2vec nor GloVe can provide a vector representation of words that do not exist in the dictionary. So in this respect, fastText performs better than the above two methods, especially on small data sets.
However, although some progress has been made, there is still a lot of work to be done on the NLP side. For example, the powerful NLP framework spaCy can integrate word embedding into a deep learning model in a local way, accomplishing tasks such as NER or Dependency Parsing, allowing users to update or use their own models.
I believe that in the future, it is appropriate to use pre-trained models for specific areas that are easy to use in the NLP framework (eg biology, literature, economics, etc.). For us, if we can adjust them in the easiest way, it is even more icing on the cake. At the same time, methods that can accommodate word embedding begin to emerge.
Apply generic embedded to specific application cases
The main disadvantage of using pre-trained word embedding is that there is a word distributional gap between the training data and the data in the actual problem. If you have a essay on a biological paper, a recipe, or an economics research paper, but don't have a large corpus to train good embedding, you'll end up with a generic word embedding to help you improve your results. But what if you can adjust the generic embedding to suit your individual case?
This adaptation is often referred to as cross-domain or domain adaptation in NLP and is very close to migration learning. Yang et al. proposed a regularized skip-gram model this year. Given the embedding of the source domain, it is a very interesting study to learn the embedding of the target domain.
The important ideas are simple and efficient. Suppose we know that the word of the word w in the original source field is embedded as ws. In order to calculate the embedding of wt in the target domain, a specific amount of migration ws is added between the two domains. In general, if the word appears frequently in both domains, its semantics are independent. In this case, the larger the value of the migration, the more similar the embedded result may be in both domains. Conversely, if a word appears more frequently in one domain than another, the value of the migration is small.
Research on this topic has not been carried out in depth, but I believe that more people will pay attention to it in the near future.
Emotional text analysis incredible side effects
Great inventions are often unexpected, and the achievements to be made below are no exception. This year, Radford et al. studied the characteristics of the byte-level circular language model in order to predict the next character in Amazon's comment text. In the process, however, they found that a single neuron in the training model was able to highly predict the sentiment value of the article. This single "sentiment neuron" can classify comments into positive or negative categories in a fairly accurate manner.
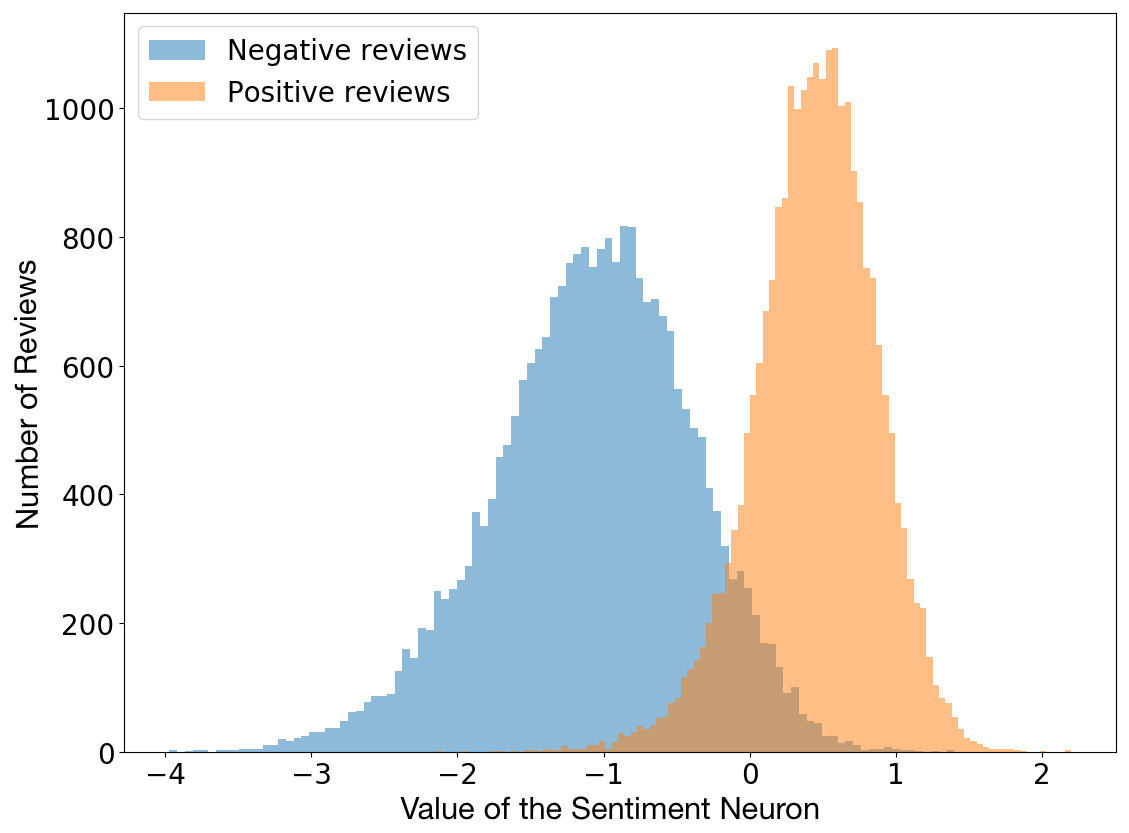
Comment on polar vs neuron values
After discovering this feature, the authors decided to apply the model to the Stanford Sentiment Treebank dataset, resulting in an accuracy of 91.8%, which is higher than the previous best 90.2%. This means that their models are trained in an unsupervised manner and achieve the most advanced emotional text analysis results with less training data.
Emotional neuron work process
Since the model works at the character level, it can be seen that the neurons can change the special character color when making judgments in the text. As shown below:

After the word "best", the neuron turns the text dark green (representing positive), and after the word "horrendous", the green disappears, indicating that the emotion turns from positive to negative.
Generate polar biased text
Of course, the trained model is an efficient model, so you can also use it to generate text like Amazon's comments. However, I think the great thing is that you can simply rewrite the value of the emotional neuron to determine the polarity of the generated text.
| This is the best hammock I have ever bought! It won't deform at all, and it's super comfortable. I like the print above and it looks so cute! | You can't use it at all, just eat a long one. |
| This is what I want. This pair of trousers fits perfectly and the lines are very precise. It is highly recommended! | The package turned out to be empty and there is no QR code. Wasting time and money. |
The neural network model chosen by the author is the multiplicative LSTM proposed by Krause et al in 2016, mainly because they observed that the hyperparameter setting of the model converges faster than the normal LSTM. It has 4096 units and the training corpus contains 82 million Amazon comments.
At the same time, you can also try to train your own model and experiment. Of course, this requires you to have enough time and a powerful GPU: the author of the paper spent a month on the NVIDIA Pascal GPU to train the model.
Analysis of emotional text on Twitter
To analyze people's evaluation of a brand, or to analyze the impact of a marketing campaign, or even to measure people's feelings about the presidential election, emotional analysis in Twitter is a very powerful tool.
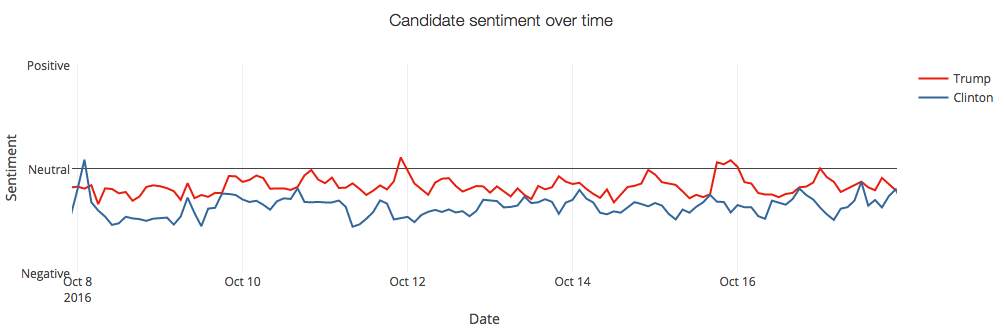
Twitter's sentiment analysis of Trump and Hillary's tweets
SemEval 2017
The analysis of emotional texts in Twitter has attracted the attention of NLP researchers, and has also attracted the attention of the political and social sciences. So since 2013, the international semantic assessment SemEval has proposed a specific task.
In 2017, a total of 48 teams participated in the selection. The following five subtasks will let you know what SemEval has analyzed on Twitter.
A: Given a tweet, judge whether it is positive or negative or neutral.
B: Given a tweet and topic, classify the emotions conveyed in the topic: positive or negative.
C: Given a tweet and topic, the emotions conveyed in the tweet are divided into five categories: very positive, generally positive, neutral, generally negative, and very negative.
D: Given a set of tweets on a topic, estimate the distribution of these tweets in positive and negative.
E: Given a set of tweets on a topic, the sentiments are divided into five categories: very positive, generally positive, neutral, generally negative, and very negative.
It can be seen that the A task is the most common task, a total of 38 teams participated in this task, and other items are more difficult. The organizers pointed out that the team using deep learning methods this year is more conspicuous and growing, and 20 teams use models such as CNN and LSTM. In addition, although the SVM model is still very popular, several teams have combined them with methods such as neural networks or word embedding.
BB_twtr system
I think the most noteworthy thing this year is a pure deep learning system, BB_twtr, which ranks first among the five sub-tasks in English. The authors combine 10 CNNs and 10 biLSTM collections, trained with different hyperparameters and different pre-training strategies. The details of the neural network architecture can be seen in the paper.
To train these models, the author used a tweet with a topic tag (a total of 49,693 tweets in the A task), and then created a tweet data set containing 100 million unlabeled, with a similar smile. The tweet is classified as positive, and vice versa as negative, and the derived data set is again established. Here, tweets are turned into lowercase and marked with symbols; URLs and emojis are replaced with special symbols; duplicate letters are merged, for example "niiice" and "niiiiiiiice" become "niice" .
To pre-train the input word embedding used as CNN and biLSTM, the author trained on unlabeled data sets using word2vec, GloVe, and fastText with default settings. He then uses the derived data set to improve the embedding, adds polarity information, and then improves it again with the tagged data set.
Experiments using previous SemEval datasets show that using GloVe reduces performance and does not have a best model for all gold standard datasets. The author then combined all the models with the soft voting strategy, resulting in a model that was better than the best results in 2014 and 2016, close to the best results of 2015. It ended up in the top of the five sub-tasks of 2017SemEval.
Even if this combination is not done in an organic way, but by adding a simple soft voting strategy, it also shows that the potential for applying the deep learning model is very large, and it also proves that almost all end-to-end methods are Emotional analysis in Twitter can go beyond supervised methods (inputs must be pre-processed).
Exciting abstract summary system
Automatic summarization is one of the earliest tasks of NLP. There are two main ways: extraction-based and abstract-based. The extractive automatic summarization method is to extract abstracts by extracting existing keywords and sentences in the document; the generated automatic summarization method is to form abstracts by establishing abstract semantic representations and using natural language generation techniques. In the past, extraction was the most common method because they were simpler than the other.
In the past few years, RNN-based models have achieved amazing results in text generation. They perform very well for short text input and output. But when it comes to long text, it often outputs incoherent, repetitive results. In their work, Paulus et al. proposed a new neural network model to overcome this limitation and achieved exciting results, as shown below:

Automatic summary generation model
The author uses the biLSTM encoder to read the input and uses the LSTM decoder to generate the output. Their main contribution was the creation of a new internal attention strategy that focused on input and continuous output, and a new training method that combined the criteria for supervised term prediction with reinforcement learning.
Internal attention strategy
The purpose of the new internal attention strategy is to avoid duplication in the output. In order to achieve this, they use the attention of the cache to view the previous paragraph of the input text while decoding, and then determine the next word to be generated. This allows the model to use different parts of the input during the build process. They also allow the model to access the previous hidden state from the decoder. When the two functions are combined, the next word that best fits the output summary is selected.
Reinforcement learning
When writing a digest, two different people will use different words and sentences, but the abstracts written are correct. Therefore, judging that a digest is a good standard does not necessarily mean that it matches the word sequence in the data set completely. With this in mind, the author avoids the standard teacher forcing algorithm, which minimizes losses at each decoding step and relies on a more reliable reinforcement learning strategy.
Good results for approximate end-to-end models
The model was tested on CNN and the Daily Mail dataset and achieved unprecedented results. Under human assessment, a specific experimental result shows that readability and quality have increased. Since the input text is marked, changed to lowercase, and the number is replaced with 0, and some special objects of the data set are removed during preprocessing, it is impressive.
The first step towards a completely unsupervised machine translation
Bilingual dictionary construction is a common problem in the field of NLP. It uses the single language corpus of the source language and the target language of two languages ​​to generate word translation. Automated bilingual dictionaries can help with other NLP tasks such as information retrieval and machine translation statistics. However, most of these methods require an initial bilingual dictionary, but it is often difficult to build.
With the advent of word embedding, cross-lingual word embeddings are also produced, the purpose of which is to adjust the embedding space instead of generating a dictionary. But unfortunately, cross-language embedding also requires a bilingual dictionary or parallel corpus. Next, Conneau et al. proposed a viable method that could rely on existing supervised methods for tasks such as word translation, sentence translation retrieval, and cross-language word similarity without relying on any particular resource.
The author proposes a method of embedding two sets of words trained on a monolingual corpus as input, and then learning the mapping between the two so that the translations in the public space are similar. They use fastText to unsupervised the text on Wikipedia, as shown in the following image.
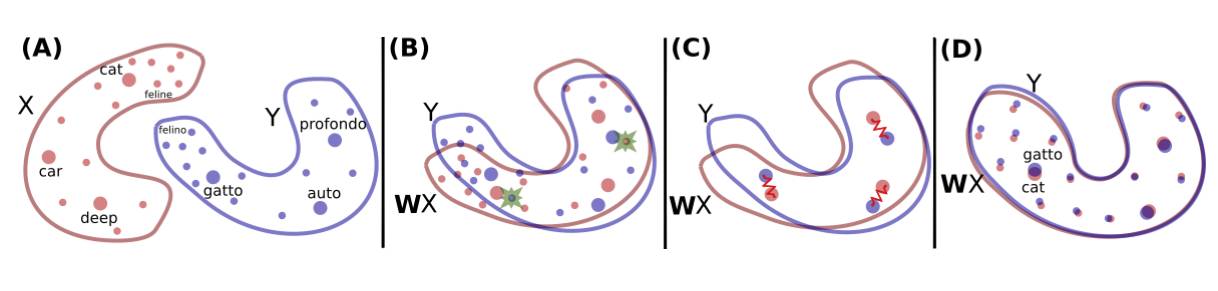
Construct a mapping between two word embedding spaces
The red X indicates the embedding of English words, and the purple Y indicates the Italian word embedding.
At the beginning, they used confrontation learning to learn the rotation matrix W, and W will perform the first original alignment. Then, after Ian Goodfellow et al. proposed generating a confrontation network, they also trained a GAN.
In order to model the problem with generative learning, they see the discriminator as a role that can make decisions. They randomly sampled from Wx and Y (second column in the figure above), and the two languages ​​belong to Wx and Y, respectively. Then they train W to prevent the discriminator from making good predictions. I think this way is very smart and elegant, and the direct result is also very good.
After that, they added two steps to improve the mapping. One is to eliminate the noise generated by rare words in the mapping calculation, and the other is to use the learned mapping and measurement distance to establish the actual translation.
In some cases, the output has exceeded the best record. For example, in the translation of words between P@10 English and Italian, they obtained an average accuracy of nearly 17% in a database of 1500 source words.
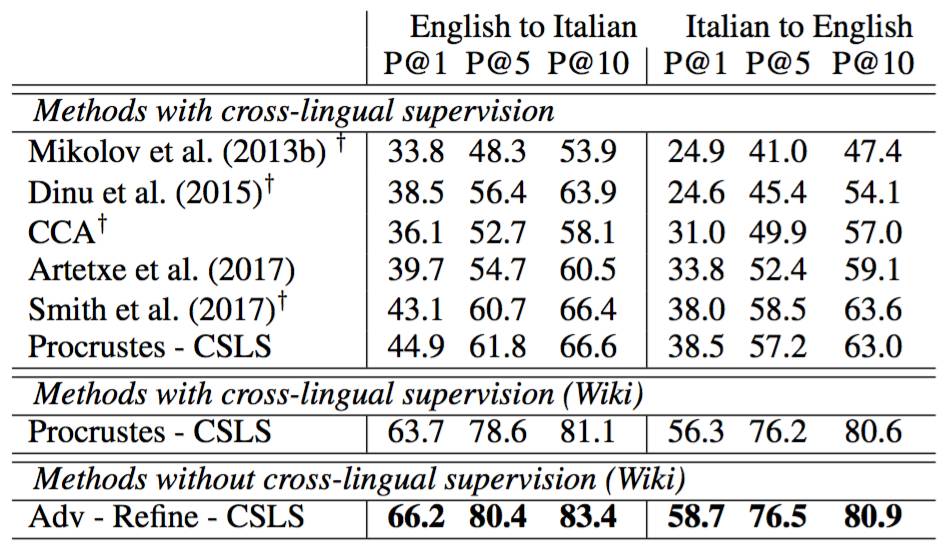
English-Italian word translation average accuracy
The authors say that their approach can be used as the first step in unlocking unsupervised machines, let us wait and see.
Special frameworks and tools
There are many common deep learning frameworks and tools available today, such as TensorFlow, Keras, PyTorch, and more. However, specific open source deep learning frameworks and tools for NLP are just emerging. This year is very important to us because there are many open source frameworks, three of which are of great interest to me.
AllenNLP
The AllenNLP framework is a platform built on top of PyTorch. It was originally designed to apply deep learning methods to perform related NLP tasks. The goal is to allow researchers to design and evaluate new models that include common NLP semantic tasks such as semantic role labeling, textual entailment, and coreference resolution.
ParlAI
The ParlAI framework is an open source software platform for conversational research. It is implemented in Python and its goal is to provide a framework for sharing, training, and testing. ParlAI provides a mechanism for easy integration with Amazon Mechanical Turk, as well as a popular data set in the field and supports a variety of models, including memory networks, seq2seq and attention LSTM.
OpenNMT
The OpenNMT toolkit is a general-purpose framework for sequence-to-sequence models that performs tasks like machine translation, summarization, image-to-text and speech recognition.
Written at the end
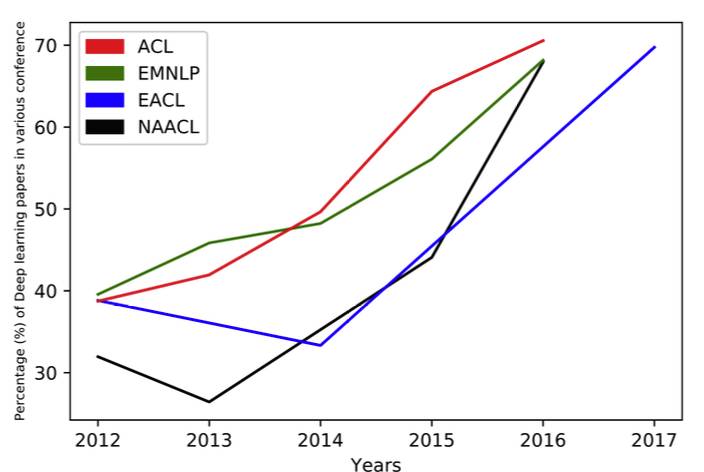
It is undeniable that the deep learning technology used in the NLP field is growing. This trend can be seen from the papers on NLP deep learning submitted by key conferences such as ACL, EMNLP, EACL, and NAACL in the past few years.
HuiZhou Superpower Technology Co.,Ltd. , https://www.spchargers.com