This article introduces a new model of transfer learning for NLP tasks, ULMFit. With only a small amount of labeled data, the text classification accuracy can reach the same level as thousands of times the amount of labeled data training. In the case of high data labeling costs and small quantities, this general language fine-tuning model can greatly reduce your NLP task training time and cost.
In this article, we will introduce the latest application trends of natural language processing (NLP) in transfer learning, and try to perform a classification task: use a data set whose content is shopping reviews on Amazon.com, which have been evaluated as positive or negative classification. Then you can follow the instructions here and re-run the experiment with your own data.
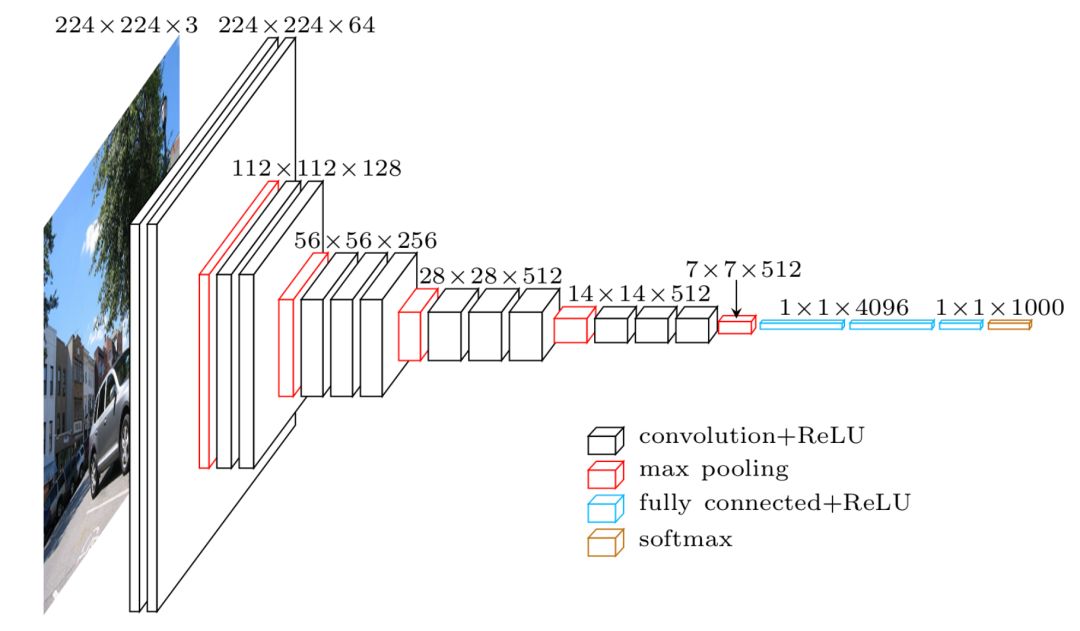
The idea of ​​the transfer learning model is this: since the middle layer can be used to learn the general knowledge of the image, we can use it as a large characterization tool. Download a pre-trained model (the model has been trained for the ImageNet task for several weeks), delete the last layer of the network (fully connected layer), add the classifier of our choice, and perform the task that suits us (if the task is for cats To classify with a dog, choose a binary classifier), and finally only train our classification layer.
Since the data we use may be different from the previously trained model data, we can also fine-tune the above steps to train all layers in a relatively short time.
In addition to being able to train faster, transfer learning is also particularly interesting. Training only in the last layer allows us to use less labeled data, while end-to-end training of the entire model requires huge amounts of data. set. The cost of labeling data is high, and it is a good way to build high-quality models without the need for large data sets.
The embarrassment of transfer learning NLP
At present, the application of deep learning in natural language processing is not as mature as the field of computer vision. In the field of computer vision, we can imagine that machines can learn to recognize edges, circles, squares, etc., and then use this knowledge to do other things, but this process is not simple for text data.
The initial trend of attempting transfer learning in NLP tasks was brought about by the term "embedded model".

Experiments have proved that adding pre-trained word vectors to the model in advance can improve the results in most NLP tasks. Therefore, it has been widely adopted by the NLP community and continues to search for higher-quality word/character/document representations. As in the field of computer vision, the pre-trained word vector can be regarded as a feature function, transforming each word in a set of features.
However, word embedding only represents the first layer of most NLP models. After that, we still need to train all RNN/CNN/custom layers from scratch.
High-level method: fine-tune the language model and add a layer of classifier on it
Earlier this year, Howard and Ruder proposed the ULMFit model as a more advanced method used in NLP transfer learning (paper address: https://arxiv.org/pdf/1801.06146.pdf).
Their idea is based on the Language Model. A language model is a model that can predict the next word based on the words already seen (for example, your smartphone can guess the next word for you when you send a text message). Just as the image classifier obtains the inherent knowledge of the image by classifying the image, if the NLP model can accurately predict the next word, it seems to be said that it has learned a lot about the structure of natural language. This knowledge can provide a high-quality initialization state, which can then be trained for custom tasks.
The ULMFit model is generally used to train a language model on a very large text corpus (such as Wikipedia) and use it as the infrastructure for building any classifier. Since your text data may be written differently from Wikipedia, you can fine-tune the parameters of the language model. Then add a classifier layer on top of this language model, and only train this layer.
Howard and Ruder suggested to "unfreeze" each layer step by step and train each layer step by step. They also proposed their own triangular learning rates (triangular learning rates) based on the previous research results on learning speed (periodical learning).
Use 100 labeled data to achieve the result of training from scratch with 20,000 labeled data
The magical conclusion of this article is that using this pre-trained language model allows us to train the classifier with less labeled data. Although the amount of unlabeled data on the web is almost endless, the cost of labeling data is high and time-consuming.
The following figure is the result they reported from the IMDb sentiment analysis task:
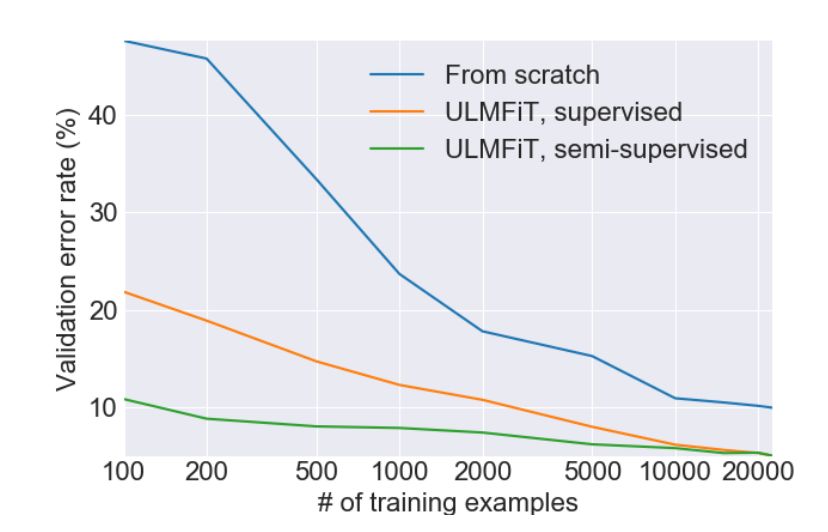
The model only uses 100 examples for training, and the error rate is similar to a model that is fully trained from start to finish with 20,000 examples.
In addition, they also provide the code in the article, and readers can choose the language of their choice and pre-train the language model. Since there are so many languages ​​on Wikipedia, we can use Wikipedia data to quickly complete the language conversion. As we all know, public label data sets are more difficult to access in languages ​​other than English. Here, you can fine-tune the language model on the unlabeled data, spend a few hours manually labeling hundreds to thousands of data points, and adapt the classifier head to your pre-trained language model to complete your own Customized tasks.
In order to deepen our understanding of this method, we tried it on a public data set. We found a data set on Kaggle. It contains 4 million reviews on Amazon products and is marked by positive/negative sentiment (i.e. good and bad reviews). We use the ULMfit model to classify these reviews into positive/negative reviews. It turns out that the model uses 1000 examples, and its classification accuracy has reached the level of the FastText model trained from scratch on the complete data set. Even when only 100 labeled examples are used, the model can still achieve good performance.
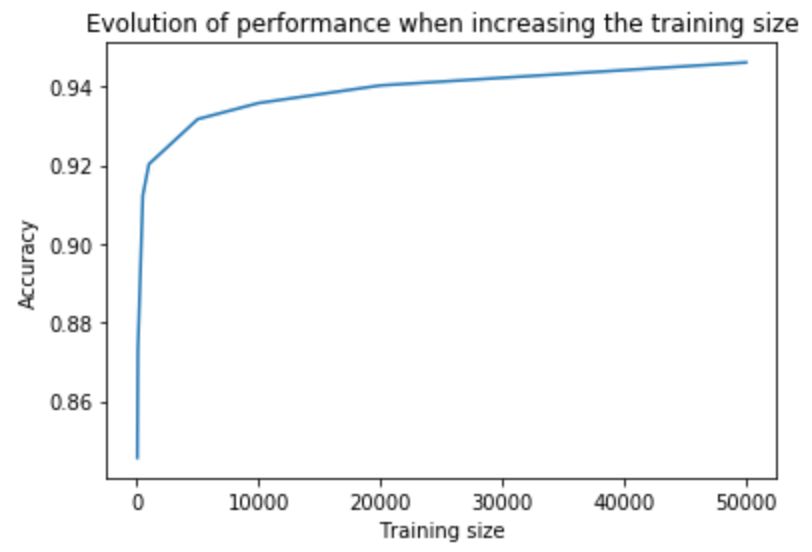
So, does the language model understand syntax or semantics?
We use the ULMFit model for supervised and unsupervised learning. The cost of training an unsupervised language model is low, because you can access an almost unlimited amount of text data online. However, using a supervised model is very expensive because of the need to label the data.
Although the language model can capture a large amount of relevant information from the structure of natural language, it is not clear whether it can capture the meaning of the text, that is, the "information or concept that the sender intends to convey" or whether it can achieve "interaction with the information receiver". communicate with".
We can think that the language model learns more about syntax than semantics. However, language models perform better than models that only predict grammar. For example, "I eat this computer" and "I hate this computer", both sentences are grammatically correct, but a language model that performs better should be able to Understand that the second sentence is more "correct" than the first sentence. The language model goes beyond simple grammar/structural understanding. Therefore, we can regard the language model as the learning of the sentence structure of natural language and help us understand the meaning of the sentence.
Due to space limitations, we will not explore the concept of semantics here (although this is an endless and fascinating topic). If you are interested, we recommend that you watch Yejin Choi's talk at ACL 2018 to discuss this topic in depth.
Fine-tuning the transfer learning language model, promising
The progress made by the ULMFit model has promoted the research of transfer learning for natural language processing. For NLP tasks, this is an exciting thing, and other fine-tuned language models have begun to appear, especially the fine-tuned migration language model (FineTuneTransformer LM).
We also noticed that with the emergence of better language models, we can even improve this knowledge transfer. An efficient NLP framework is very promising for solving the problem of transfer learning, especially for languages ​​with common sub-word structures, such as German. The performance prospects of language models trained at the word level are very good.
how about it? Try it now~
The multi-speed air supply mode can bring you a comfortable and cool breeze in various scenarios. The 180° wide-angle surrounds the healthy and refreshing natural wind, and the soft wind blows on the face, returning to the natural and refreshing. The fuselage is equipped with a lanyard, so you can take the wind with you anytime anywhere.
Neck Fan,Small Fan,Portable Mini Fan,Hanging Neck Fan
Dongguan Yuhua Electronic Plastic Technology Co.,Ltd , https://www.yuhuaportablefan.com